Small improvements for big advancement
Kaggle competiton journey continues! After solving duplicate question challenge with simple stats-based techniques in my first post and investigating deep learning solutions in the second other approaches to improve the result were tried.
Brief summary
Two previous posts describe two different approaches to solving duplicate questions challenge I was interested in DL-based (neural networks and friends) and “vanilla” (with manual feature engineering and non-DL classifiers).
TF-IDF and SVD approach (described in the first post) scored at 0.79 with kaggle LB (leaderboard) loss of 0.44, and the position was 765/1281 (top 60%).
Final deep neural network approach (1 LSTM layer and 4 fully connected) got loss 0.36134 at kaggle board, and the position was 659/1474 (top 45%).
Things worth trying
The main accent of this writing is about
- data cleaning and preprocessing,
- train/test data class balancing,
- ensembling learning and
- hyperparameter tuning.
At the very beginning of the current week I had “primitive” neural model with 1 LSTM embedding layer and a couple of fully connected ones on top of that. Very simple model without any feature engineering already achieved good enough results.
I was inspired by this published kernel where @lystdo follows (or at least describes) approximately similar approach: trade one GPU for all manual feature engineering :) This is overly simplified, of course.
So the model was changed (a little - 4 fully connected layers were used instead of 2) to reflect the model described and the goal was to replicate results. The author claimed one model could achieve kaggle score (loss) of 0.29-0.30 while ensemble could score as high as 0.28+. Numbers look very promising, so let’s start!

Several things to mention (I’m reusing picture from previous blog post):
- I was using 4
Dense(fully connected) layers and not 2 - One LSTM cell was used instead of 2
- GloVe embeddings were used instead of word2vec
- Activation functions, dropout, and batch normalization layers are not shown
- There were slight differences in
Concatlayer (see below)
Model definition with chainer is:
class SimpleModel(chainer.Chain):
INPUT_DIM = 300
def __init__(self, vocab_size, lstm_units, dense_units, lstm_dropout=0.0, dense_dropout=0.0):
super().__init__(
q_embed=L.LSTM(self.INPUT_DIM, lstm_units),
fc1=L.Linear(2 * lstm_units, dense_units),
fc2=L.Linear(dense_units, dense_units),
fc3=L.Linear(dense_units, dense_units),
fc4=L.Linear(dense_units, 2),
bn1=L.BatchNormalization(2 * lstm_units),
bn2=L.BatchNormalization(dense_units),
bn3=L.BatchNormalization(dense_units),
bn4=L.BatchNormalization(dense_units),
)
self.embed = L.EmbedID(vocab_size, self.INPUT_DIM)
self.lstm_dropout = lstm_dropout
self.dense_dropout = dense_dropout
self.train = True
def __call__(self, x1, x2):
x1 = self.embed(x1)
x2 = self.embed(x2)
seq_length = x1.shape[1]
self.q_embed.reset_state()
for step in range(seq_length):
q1_f = F.dropout(self.q_embed(x1[:, step, :]), self.lstm_dropout, self.train)
self.q_embed.reset_state()
for step in range(seq_length):
q2_f = F.dropout(self.q_embed(x2[:, step, :]), self.lstm_dropout, self.train)
x = F.concat([
F.absolute(q1_f - q2_f),
q1_f * q2_f], axis=1)
x = F.relu(self.fc1(F.dropout(self.bn1(x, not self.train), self.dense_dropout, self.train)))
x = F.relu(self.fc2(F.dropout(self.bn2(x, not self.train), self.dense_dropout, self.train)))
x = F.relu(self.fc3(F.dropout(self.bn3(x, not self.train), self.dense_dropout, self.train)))
x = self.fc4(F.dropout(self.bn4(x, not self.train), self.dense_dropout, self.train))
return x
Taking feature construction idea from quora enginnering blog, distance (absolute difference \(F_1 = \|q_1 - q_2\|\) ) and angle (element-wise multiplication \(F_2 = q_1 \odot q_2\) ) between question representation vectors were taken instead of just concatenating vectors.
To make a model more robust to overfitting L2 regularization was used via weights decay with \(\alpha = 1e-4\). Validation loss improved to 0.376441.
optimizer.add_hook(chainer.optimizer.WeightDecay(1e-4))
It was time for submission, and kaggle LB loss was 0.38354 that was slightly worse than the previous submission. Clearly, the model didn’t improve much.
Class balancing
After immersing into forum and kernel discussions one can find that people are concerned about training and test sets class imbalance. This thread is a nice summary of what it is and how to combat this issue. In short, training set has 37% ratio of positive (duplicate) classes and test set (one against which the models are scored) has the different one (current community thinking is 16.5%). Sure, we want them to be equal. But if they’re not and we can employ the simple technique for better results.
# those are probabilites from our model
predictions = model.predict(test_set)
a, b = 0.165 / 0.37, (1 - 0.165) / (1 - 0.37)
# those are modified, to be submitted
predictions = a * predictions / (a * predictions + b * (1 - predictions))
I used this code to reweight predictions before submissions. Once I started using this simple trick kaggle submission loss jumped (down) from 0.38354 to 0.32539. Yeah! That positions the model at 307/1669, top 19% result! Awesome. From now on I always used this trick.
Some tuning
At the time I started doing small changes to the model parameters hoping to improve the result. I tried different variations of batch size, weight decay rate, recurrent and dense layers dropout rates. Eventually, I found that lstm_dropout rate better be zero (i.e. no dropout for hidden-to-hidden connections), 0.3 dense_dropout is better than 0.15, the batch size of 128 allows better loss than of 4096 (though it takes longer to train because of low GPU utilization).
Another important change was made to the dense layers ordering. In particular, I changed batch normalization, activation, and dropout applications to more “proper” way as described in dropout and batch normalization papers.
- x = F.relu(self.fc1(F.dropout(self.bn1(x, not self.train), self.dense_dropout, self.train)))
+ x = self.fc1(F.dropout(F.relu(self.bn1(x, not self.train)), self.dense_dropout, self.train))
Using this tweaks allowed to get 0.31292 kaggle loss, position updated to 274/1723. Little, but still an improvement.
Data cleaning and preprocessing
All the time I was worried about not doing any text cleaning and/or preprocessing. Now it was the time to try to do it, as many kaggles are already doing.
But before that other idea was about to be checked - different pretrained embeddings:
I found that using gensim allowed to eliminate code for loading different embeddings.
from gensim.models import KeyedVectors
binary = True if 'Google' in path else False
word2vec = KeyedVectors.load_word2vec_format(path, binary=binary)
GloVe embeddings have to be transofmed with following command to have compatible format:
python3 -m gensim.scripts.glove2word2vec -i glove.840B.300d.txt -o glove.840B.300d_gensim.txt
For that series of experiments I used best-so-far parameters and just trained four different models. Meantime, data preprocessing routine was implemented. Results for different embeddings and data preprocessing impact are below:
| Cleaning | word2vec | lexvec | fasttext | GloVe |
|---|---|---|---|---|
| no | 0.357437 | 0.358313 | - | 0.331588 |
| yes | 0.360938 | 0.352936 | 0.341722 | 0.327281 |
B=128, dense_dropout=0.3 |
0.33323 | 0.325456 | 0.31710 | 0.31168 |
Here is preprocessing routine used. It’s not the best but is a good start.
punctuation='["\'?,\.‘’“”`…]' # I will replace all these punctuation with ''
abbr_dict={
"what's":"what is",
"what're":"what are",
"who's":"who is",
"who're":"who are",
"where's":"where is",
"where're":"where are",
"when's":"when is",
"when're":"when are",
"how's":"how is",
"how're":"how are",
"i'm":"i am",
"we're":"we are",
"you're":"you are",
"they're":"they are",
"it's":"it is",
"he's":"he is",
"she's":"she is",
"that's":"that is",
"there's":"there is",
"there're":"there are",
"i've":"i have",
"we've":"we have",
"you've":"you have",
"they've":"they have",
"who've":"who have",
"would've":"would have",
"not've":"not have",
"i'll":"i will",
"we'll":"we will",
"you'll":"you will",
"he'll":"he will",
"she'll":"she will",
"it'll":"it will",
"they'll":"they will",
"i'd":"i would",
"we'd":"we would",
"you'd":"you would",
"he'd":"he would",
"she'd":"she would",
"it'd":"it would",
"they'd":"they would",
"isn't":"is not",
"wasn't":"was not",
"aren't":"are not",
"weren't":"were not",
"can't":"can not",
"couldn't":"could not",
"don't":"do not",
"didn't":"did not",
"shouldn't":"should not",
"wouldn't":"would not",
"doesn't":"does not",
"haven't":"have not",
"hasn't":"has not",
"hadn't":"had not",
"won't":"will not",
'[\'’`]s': '',
punctuation: '',
'\s+':' ', # replace multi space with one single space
}
def process_data(data):
data.question1 = data.question1.str.lower() # conver to lower case
data.question2 = data.question2.str.lower()
data.question1 = data.question1.astype(str)
data.question2 = data.question2.astype(str)
data.replace(abbr_dict,regex=True,inplace=True)
return data
As to experiments, GloVe embeddings are superior to all others. Also, we can be sure now that text cleaning and preprocessing does help.
Ensembling
Ensembling idea is vital for kaggle competitions, for example, look at this quora answer.
I tried to submit the best-so-far model from overnight training (one that had loss of 0.31168) and kaggle loss was 0.30379, slight improvement, position improved to 242/1771. But! I had another model I wanted to try to submit and tried my luck with fasttext embeddings (that had a loss of 0.3171). Interestingly, kaggle loss was better for it: 0.30176, the position is 232/1771. Finally, it was a point where I decided to try ensembling.
I had only 4 recent models, all trained with different embeddings, different initializations, and noise introduced by dropout. I tried the most simple ensembling: averaging. Submission time: loss is 0.26877, the position is 75/1771. Boom! This is a drastic improvement! I need to start doing meta-learning, that is, train a model that would combine all models into one committee.
Things also tried
I’d also like to share my experience with other interesting things I tried but didn’t succeed.
First, I was interested in bidirectional LSTM layers instead of unidirectional. Recent paper Bilateral Multi-Perspective Matching for Natural Language Sentences that claims to achieve state-of-the-art performance on the task uses bidirectional layers, and that inspired me to also try them. While it increased training time (twice) it didn’t offer any performance increase.
I also tried to do “advanced” text preprocessing with stemming, lemmatization and stopwords removal.
from nltk.stem.snowball import SnowballStemmer
from nltk.stem import WordNetLemmatizer
from nltk.corpus import stopwords
stops = set(stopwords.words("english"))
stemmer = SnowballStemmer('english')
lemmatizer = WordNetLemmatizer()
def stem(text):
text = text.split()
# just remove stop words
stemmed_words = [word for word in text if word not in stops]
# also stem words
stemmed_words = [stemmer.stem(word) for word in text if word not in stops]
# also lemmatize words
stemmed_words = [lemmatizer.lemmatize(word) for word in text if word not in stops]
return " ".join(stemmed_words)
data.question1 = data.question1.apply(stem)
data.question2 = data.question2.apply(stem)
In the code snippet above I showed different options of preprocessing. I tried different combinations but none gave me performance increase. Rather, results were worse. My thinking it is because of embeddings stemming actually makes this unusable (it turns taking -> tak, and there is no embedding for stemmed version while there is for original). Lemmatisation also reduces information available that can be utilized by a network: there are separate embeddings for take, taking, etc.
In the previous blog post I’ve described and tried deep model by @abhishek. He has a repo with very interesting engineered features: here. One can use his code to generate additional features to utilize. So, I tried these additional 28 features. Here is architecture I experimented with:
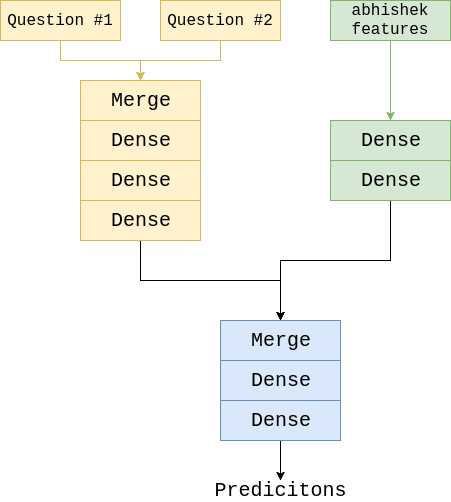
So I thought those features would pass through a couple of dense layers, and have some representation as well as LSTM-based branch. Then features from both branches merged and went through more dense layers to allow interaction. However, no improvement in performance was observed and I postponed using these features in a setup like mine.
Conclusion
There is still a lot to be done to advance further. However, I’m already pretty content with the progress and with the results achieved (top 5%). Next things I’m about to try is to replace LSTM with QRNN (they said to be more stable and robust, and also faster) and to start doing heavy meta-learning.