Intro into database storage engines
In this blog post, I’ll explore storage engines used in different database implementations, modern trends, and history legacy.
Disclaimer: I’m exploring different options with a particular goal in my mind, namely “How does CockroachDB storage engine works and how it could be improved?” So, this post is not intended to be the full coverage of all possible options. Rather it just covers what needs to be researched to understand and answer the bugging question. As a matter of fact, my interest was sparked by cockroachdb #5220 PR.
B-tree
First, let’s start with B-tree data structure because it’s then would be easier to understand current “de facto” standard in some databases (LevelDB, RocksDB, SQLite, Cassandra, BigTable, HBase) which is LSM (log-structured merge) tree.
Of course, the best place to start get yourself familiar with B-tree is wikipedia article. It offers nice intro and some decent information. The very description given by article is:
In computer science, a B-tree is a self-balancing tree data structure that keeps data sorted and allows searches, sequential access, insertions, and deletions in logarithmic time.
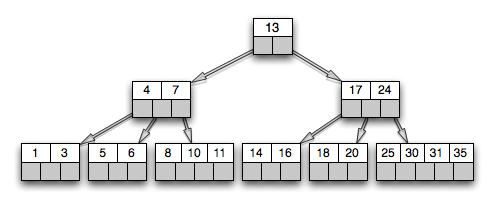
Actually, there is a variant called B+tree (note the plus) that is slightly different from the former, but details should not be that important now.
Basically, it’s a data structure that aims for “read and write large blocks of data”, and this is a good reason one can find it in databases and filesystems implementations. Particularly, database index can be implemented with it. Key point is that such trees usually grow wide and shallow, so for some type of query (remember, it’s still a search tree) only very few nodes are to be “touched”. This is important, because such access could be very expensive (think of rotating HDD).
LSM tree
Now, what LSM trees are? I found “Morning paper” blog description is a smart way to get yourself introduced to it: The Log-Structured Merge-Tree (LSM Tree).
As time passed, data grew larger, for some workloads write operations prevailed, and the need for better data structure had arisen. This is where LSM tree comes in. It proved to be well suited in the case of massive data volumes with high write/delete throughput while also leveraging different types of storage with different access cost characteristics, such as RAM, SSD, HDD, remote filesystem, etc. One of its assumptions is that random I/O access is much more expensive rather than sequential. But everything has a cost and read performance is a trade-off for engines using LSM trees in their implementations.
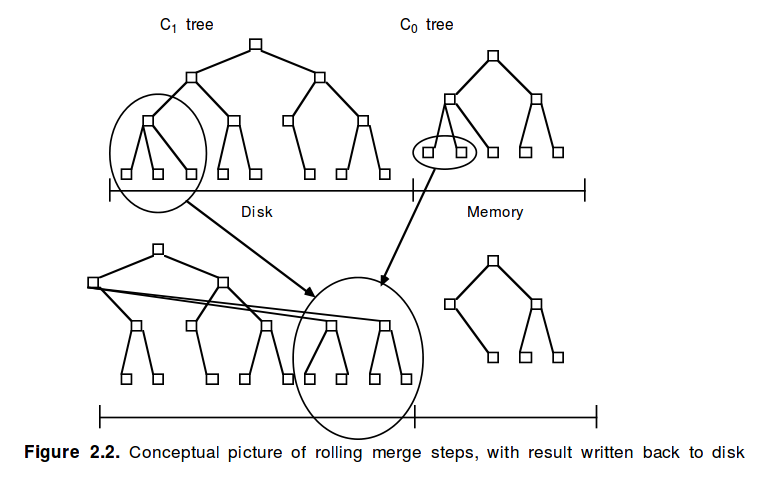
Basically, another very good place to understand LSM trees in more details is this blog post. If one is interested in in-depth understanding, he could find useful links with even more diverse and thorough description.
LevelDB

One of the databases that use LSM trees is LevelDB. It’s built by Google engineers and draws ideas from BigTable. In short, it’s an ordered embedded key-value store, that one uses as a library in an application. It’s aimed for heavy write throughput workloads while being not great at random reads. The very brief introduction could be found in this article.
In a nutshell, LevelDB uses log file (in append-only mode) for writes and several levels of sorted table files (SSTable, see the previous link).
Because of append only mode (and actually an in-memory copy of log), all write operations are fast. Once log file becomes full, it’s converted to a sorted table and placed on 0-level. There is also a limit of how many files (or how bug they are) could be on the same level. Once this threshold is exceeded, files are merged (and because they’re sorted merge operation is fast), and resulting file is placed on the next level. Main reason LevelDB needs this leveling is to perform merges using bulk reads and writes: they minimize expensive seeks (since it’s designed to work on disks).
More implementation details could be found at their github repo.
RocksDB
![]()
RocksDB is a fork of LevelDB started at Facebook, now open sourced. It was written with a goal of using it with production workloads, targeting Flash drives (SSD) and RAM, while also leveraging multiple CPU. The main difference is flexibility: tunable trade-offs for reading/writing and space usage.
It was written for performance and production usage so that it could leverage fast storage mediums like RAM and flash drives, while being able to work with slower devices like HDD and HDFS. It’s also meant to be used in production so that it has built-in tools and utilities for deployment and debugging ease, various statistics collection.
It offers much more features (and is more complex) than LevelDB, multithread inserts and column families to name a few. A full list of features could be found on their wiki page.
There is a lot to say about RocksDB, its features, and usage, lots of information to digest. Doing this is out of the scope of this post which aims to quickly outline only some storage engine implementations.
LMDB
This is a very different beast. LMDB stands for Lightning Memory-Mapped Database and uses B+trees data structure in its implementation. This database was designed for very different types of workload: reads. I would like to quote the author (Howard Chu) opinion here:
“And from a practical perspective, data stored in a DB is only useful when you actually retrieve it again and use it. (Assuming you can retrieve it again; some folks like the MongoDB guys seem to forget that detail.)” - Howard Chu.
So, blazingly fast reads were a priority during design and development. Decent write performance is a side bonus.
Just a few words about what is it and what it can: LMDB is highly optimized, fully transactional, ACID compliant key-value store. It is designed with efficiency in mind, not performance (like LevelDB and RocksDB). It provides concurrency support and uses Copy-on-Write technique to perform its tasks. Learn more about LMDB with this most recent talk.
Personally, I loved this post from Paul Banks that compares (kind of) LMDB with LevelDB and raise questions about different LMDB aspects. Moreover, the response from the author is remarkable.
Comparisons
In conclusion, I wanted to share some benchmarks and comparison results. Please note that every and each benchmark is kind of unique and aims for the very specific workload, mainly because of targeted usage.
First, here is comparison of RocksDB and LevelDB. Second, there is another one from InfluxDB guys. Their benchmark includes all three embedded databases that were reviewed in this post.
Summary
This post was written as a helper method for myself to get quick intro about what storage engines are used, their characteristics, pros, and cons. There are other lots of others that aren’t covered here and it wasn’t a goal. Apologize for a slightly misleading title!