Transactions and consistency 101
For a very long time, there were some white spots about transactions and different consistency models. Don’t get it wrong, my bet is that every engineer has some intrinsic understanding of what transaction is, knows that it somehow related to databases, that consistency has something to do with a system being in a predictable and understandable state. But being a complete self-learner, one has to skip some theoretical things and start doing practical things as soon as possible.
Transactions
It’s well known that relational DBMS are all about Relational Algebra and Entity–relationship model. In other words, ER modeling is used to represent different things in a business to perform its process and operate successfully; it is abstract data model. RDMBS are systems invented to operate on business data; they store data that is modeled with Entity-Relationship model and perform operations (queries, updates) on it.
However, there are some discrepancies of what is natural for human and for a machine. The most simple example is reading. For a man, it’s natural to think about both single letter as a unit, single word, and even single sentence. Depending on representation, single letter is atomic for a machine, but words and sentences are not atomic but are sequences of others objects (let’s not consider word2vec representations for now).
With ER modeling introduced some natural business operations are atomic in human mind but not for a machine. The classic example is money transfer: for us (people) it single/indivisible operation. But from the machine point of view (again, depends on representation, i.e. modeling) it could be comprised of a sequence of actions. Transaction then is a way to enforce high-level abstractions and correctness on an inherently low-level system.
To quote Stanford CS145 class:
A transaction (“TXN”) is a sequence of one or more operations (reads or writes) which reflects a single real world transition.
But keeping system state consistent (“correct”) is not the only motivation for transactions: another one is concurrency that allows much better performance.
Traditionally, one speaks about ACID properties of a transaction: atomicity, consistency, isolation and durability. To make the story complete, atomicity requires a transaction to either happen or not, durability states change made by transaction persist. But here we will focus on isolation and consistency.
Consistency models
First, let’s start with some properties. On one hand, there is linearizability that has nothing to do with transactions but rather with a single global state (or just single object). It is a real-time guarantee that all operations appear instantaneous: no overlap, no interference. Once you write something, subsequent reads return that “something”. For example, the hardware provides atomic compare-and-swap operation.
On the other hand, there is a property called serializability. This relates to transactions. Basically, this is a guarantee that a set of transactions over multiple objects is an equivalent of some serial (that is, as each transaction applied at a time - total ordering) execution. Consider two transactions that themselves are consistently executed simultaneously:

Here (sample courtesy of CS145 2016) first transaction (red) transfers $100 from account A to account B. Blue transactions applies 6% interest rate to both of them.
This execution order (interleaved, both transactions happen simultaneously) is not equivalent to serial execution (red, then blue or blue, then red).

However, such interleave is equivalent to “red, then blue” order. Hence, this set of transactions has a property of serializability.
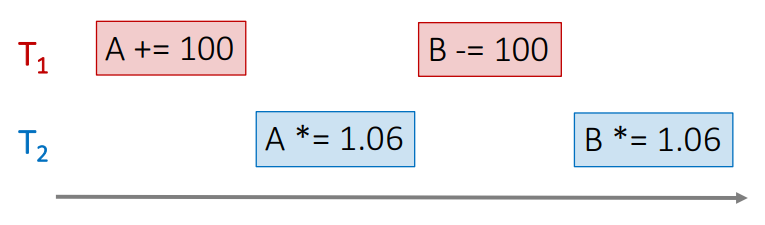
Note that this guarantee says nothing about single operations order (no real-time constraints as for linearizability). All it assumes is that there exists some serial execution order for transactions.
Combining the two we get strict (strong) serializabilty. For quick explanation let me just quote wiki (emphasis mine):
This is the most rigid model and is impossible to implement without forgoing performance. In this model, the programmer’s expected result will be received every time. It is deterministic.
I wish I had time to describe models that are “descendants” of sequential consistency. However, this post is mainly about transactions. So let’s continue with “serializable” ones. We’re following the right path from this image:
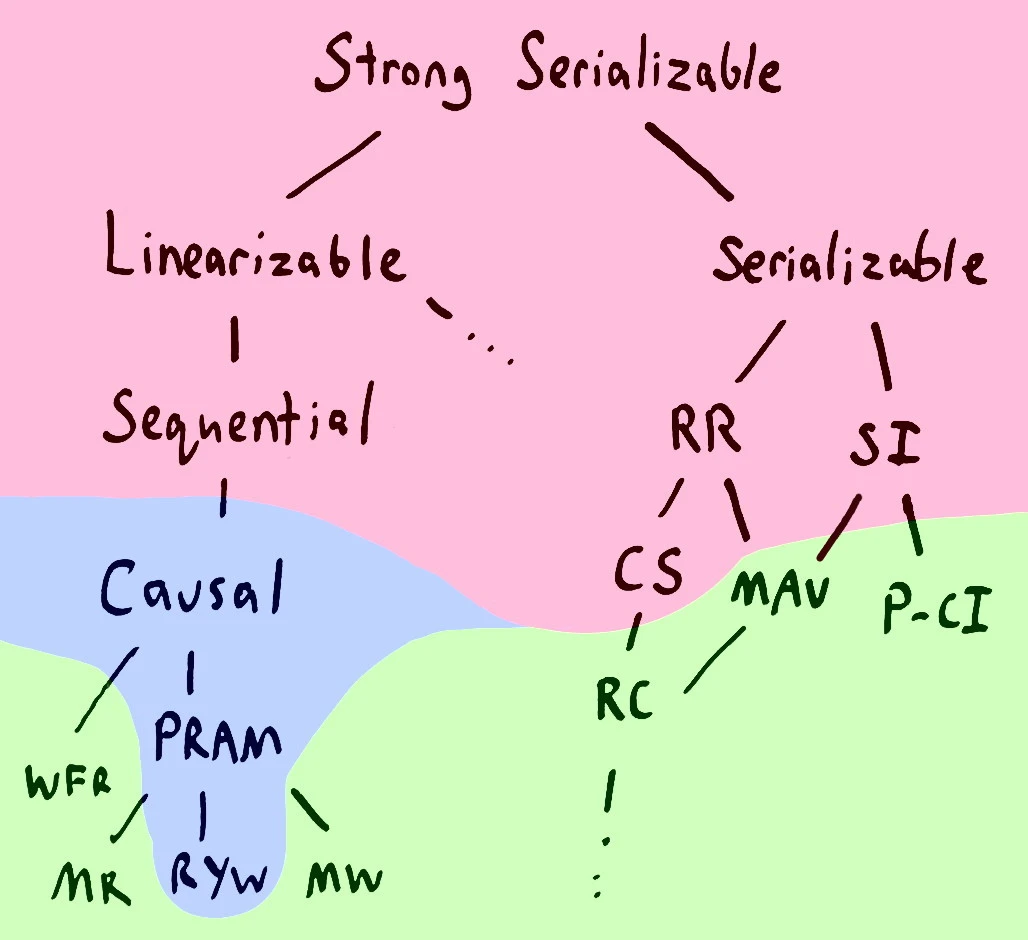
Okay, back to transactions then. Serializability is a useful concept because it allows programmers to ignore issues related to concurrency when they code transactions. But it seems that:
To complicate matters further, what most SQL databases term the SERIALIZABLE consistency level actually means something weaker, like repeatable read, cursor stability, or snapshot isolation.
By weakening our models we improve performance but it requires additional effort from a programmer to maintain correctness. Let’s explain those RR, SI, CS and RC abbreviations.
As a reference, I’d like to use Morning paper overview of Critique of ANSI SQL isolation levels. Really, I can’t help being overly excited by Adrian Colyer job was done in his field! So, for very brief overview one can follow this post, more details are available in “Morning Paper” post, and even more, technical details are available in the paper itself.
ANSI SQL defines different isolation levels and phenomena (well, the standard doesn’t define those actually). Different isolation levels eliminate different phenomenon (anomalies). Let’s start with the bottom (images taken from “Morning paper” blog post).
Dirty write occurs when one transaction overwrites value written but not yet committed by another.
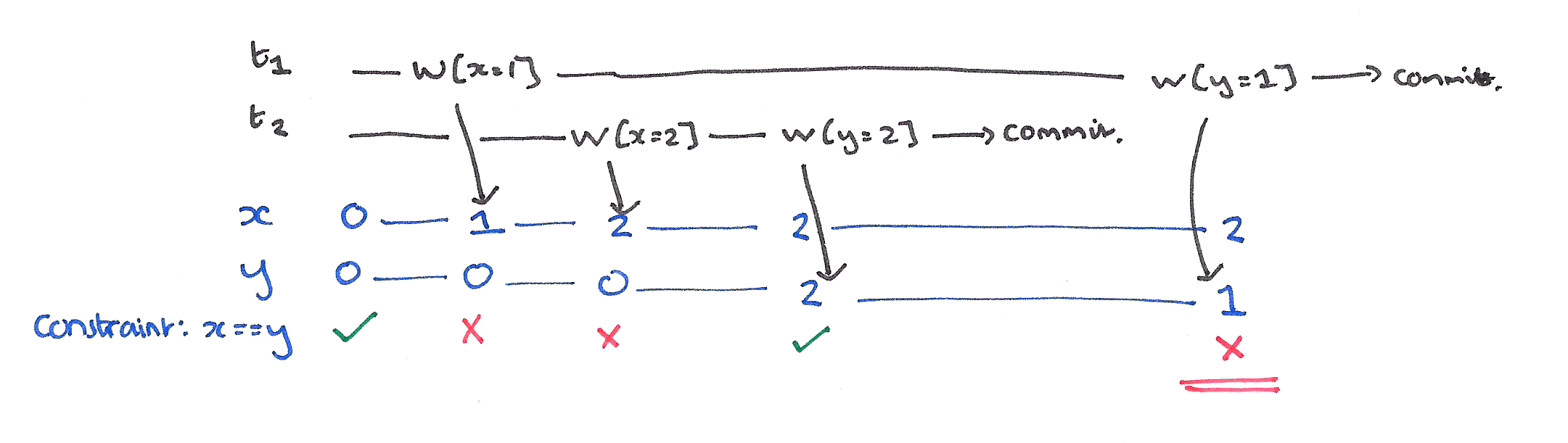
Dirty read occurs when one transaction reads a value that was written by the uncommitted transaction. If latter rollbacks, former ends up with inconsistent value.
Read Committed (RC) isolation level eliminates these phenomena.
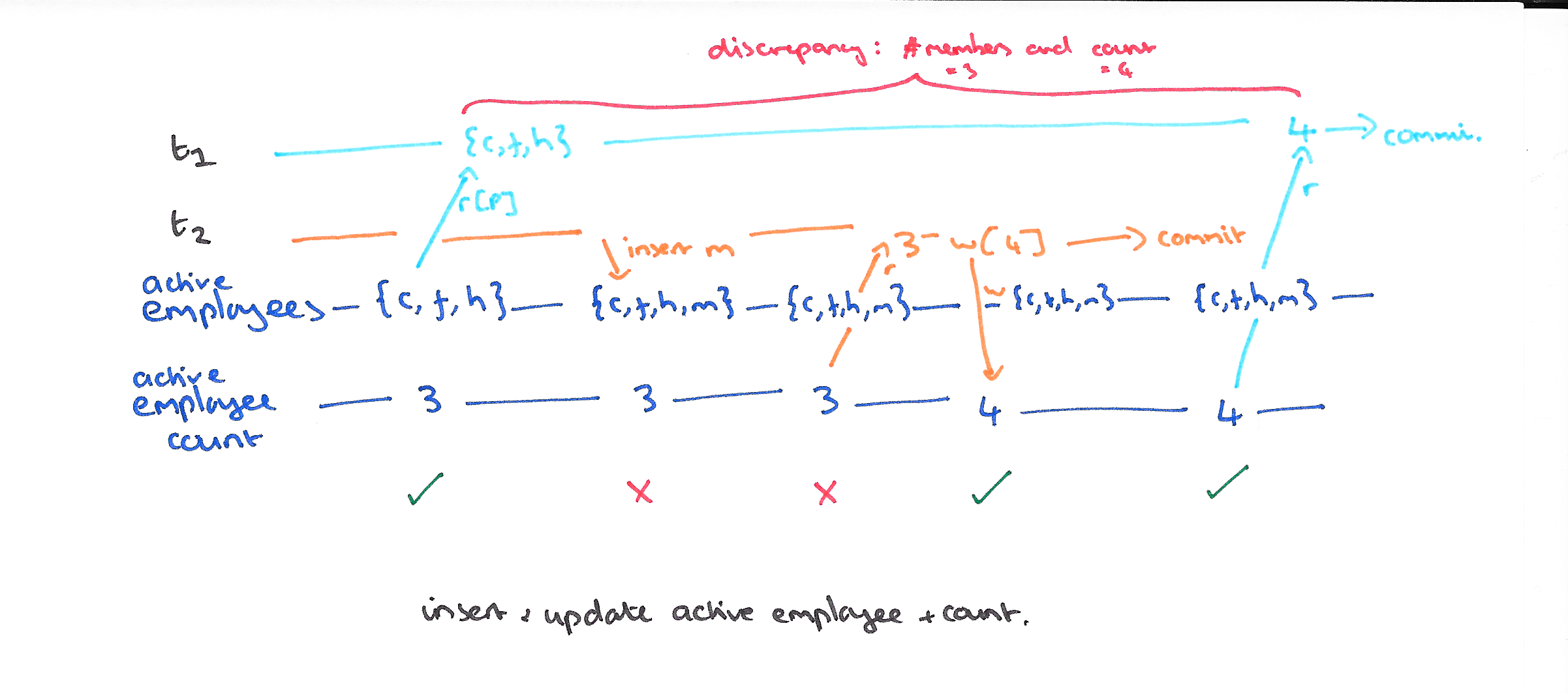
Lost update happens when two concurrent transactions read and then update (probably based on a value they read) the same item.
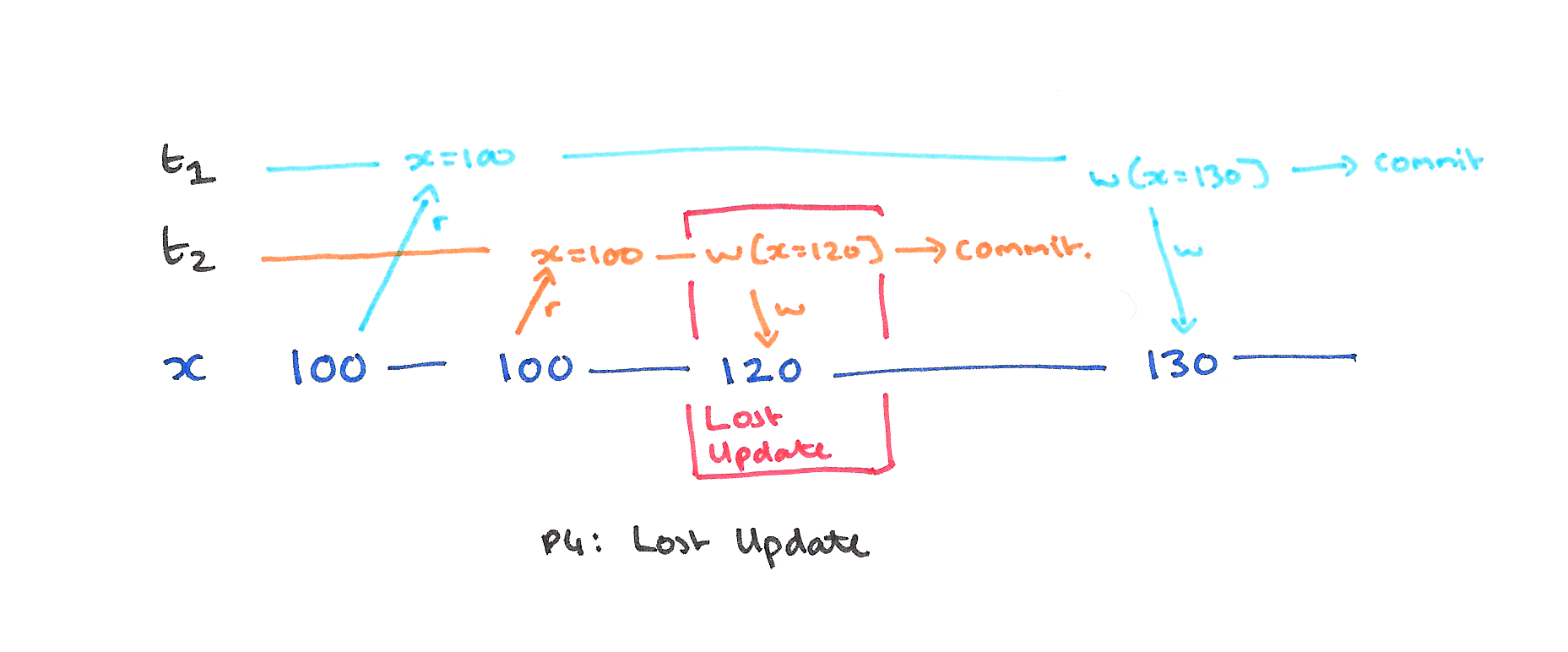 .
.
Cursor Stability (CS) eliminates it (for additional details consult the post and paper, this is not quite correct just simple to understand).
Fuzzy read happens when the first transaction subsequent reads return different result due to the second transaction modifies item accessed.
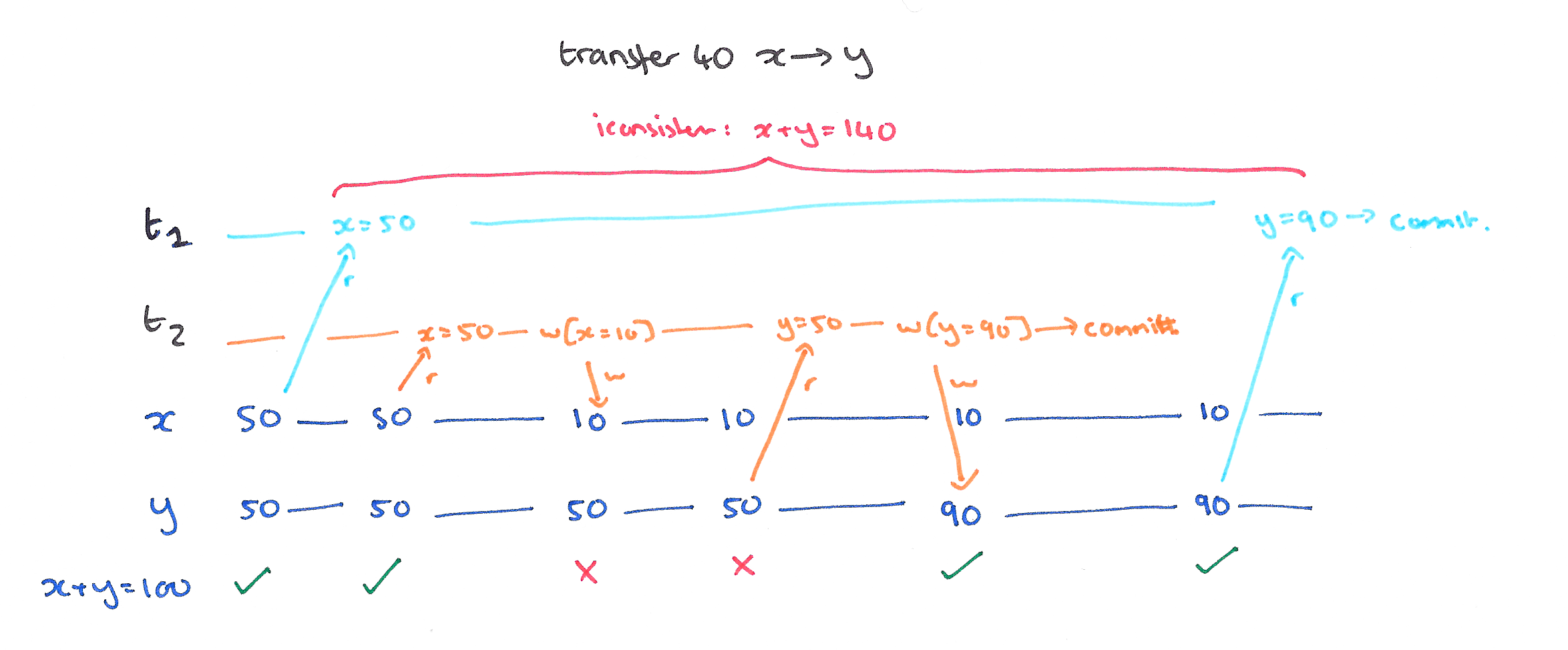
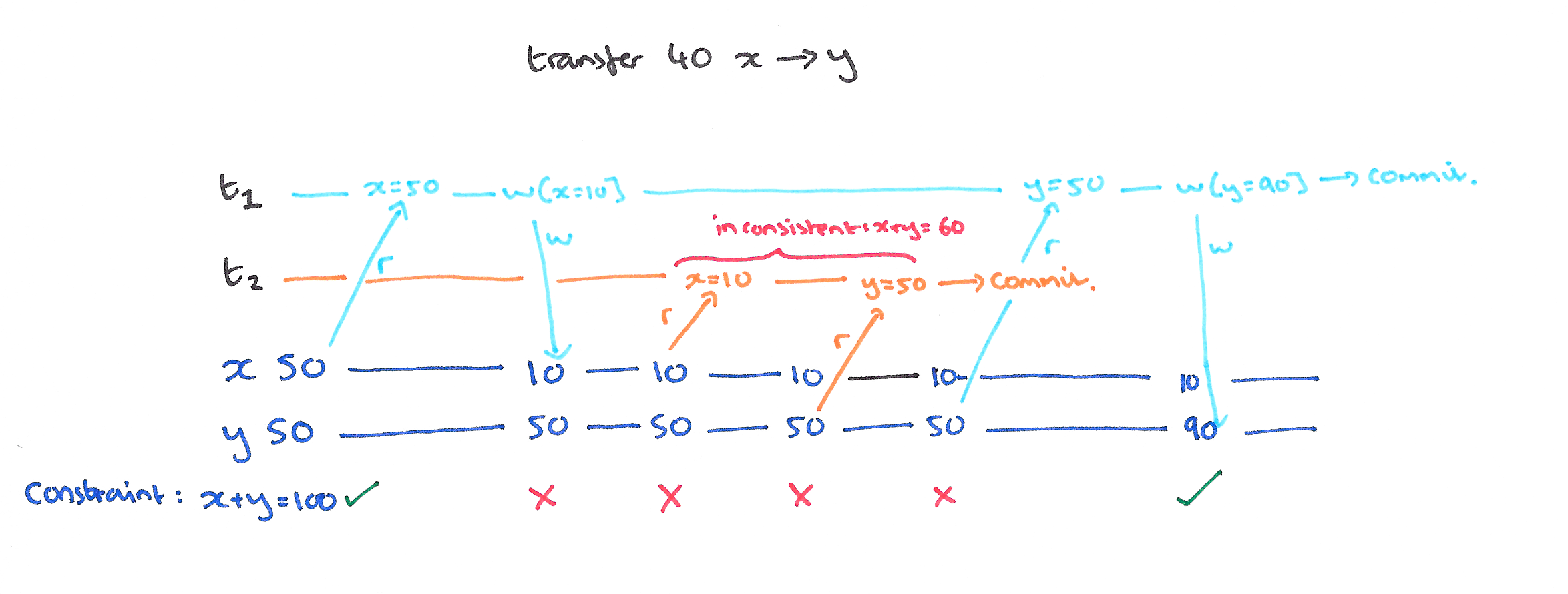
Read skew and write skew are a database constrain violations. Consider following integrity constrains: \(x + y == 100\) for the first image and \(x + y \leq 100\) for the second:
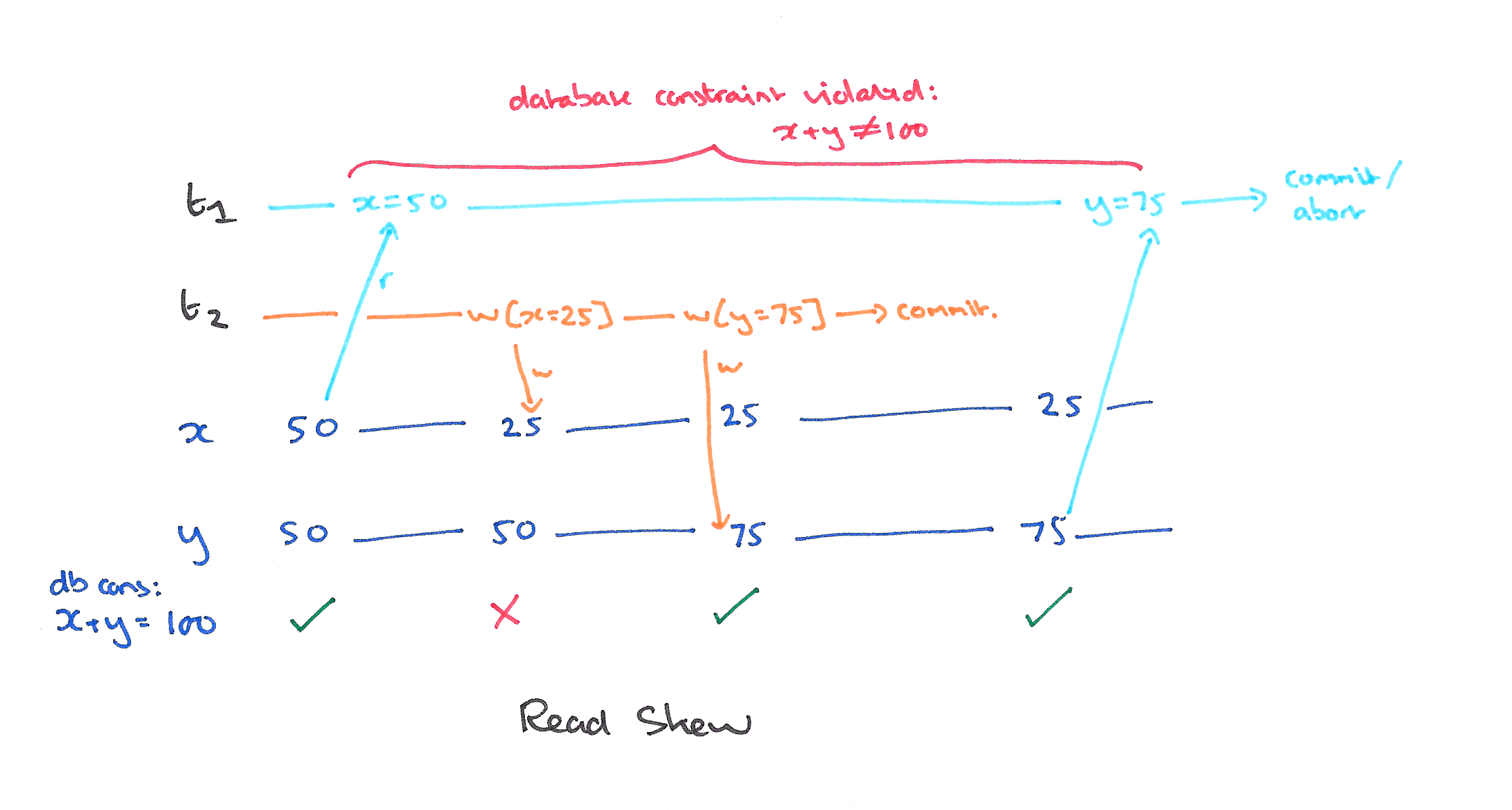
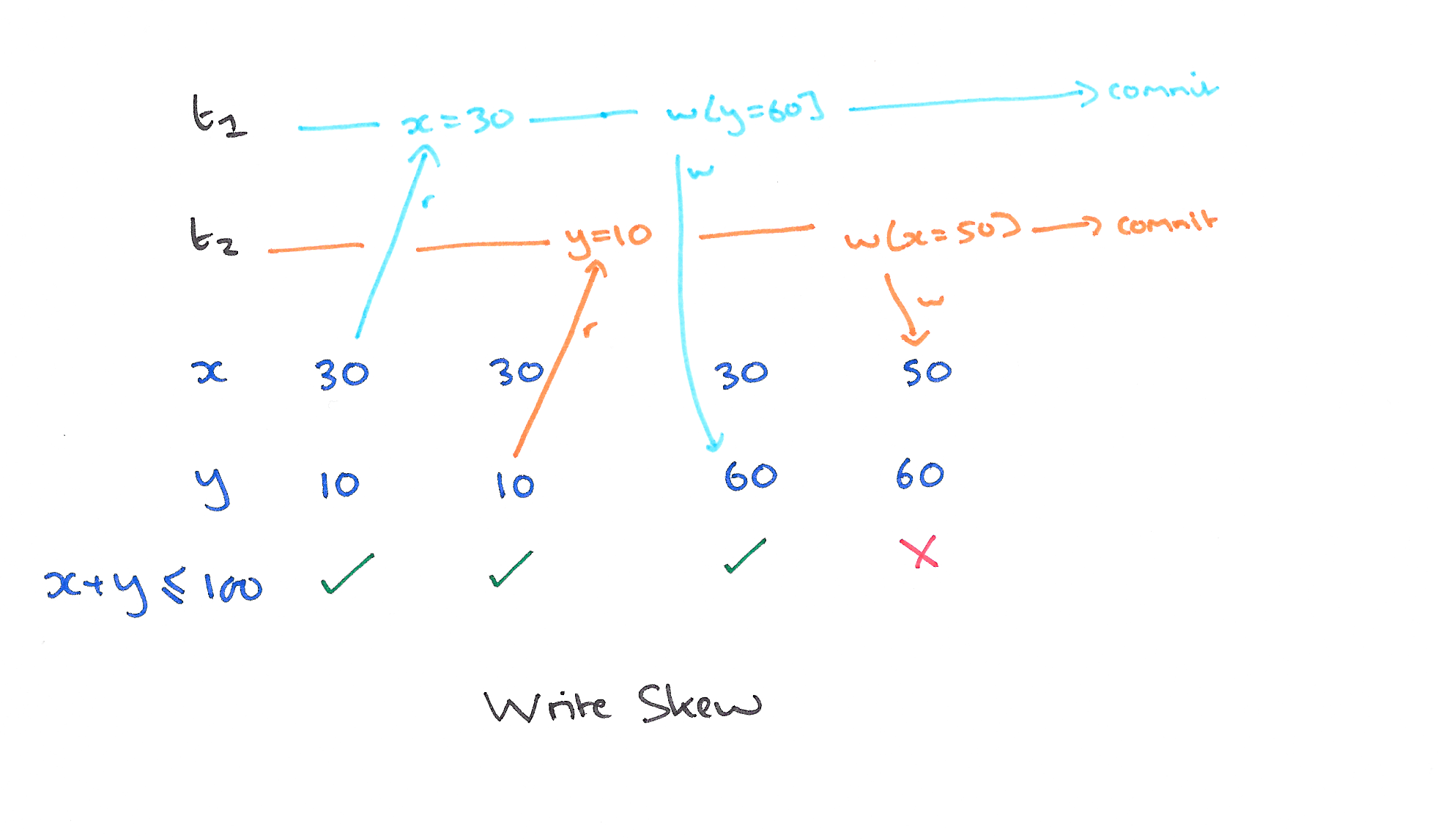
Repetable Read (RR) eliminates those three.
Snapshot Isolation, like RR, is stronger level than RC but weaker than Serializable. It belongs to MVCC (Multiversion concurrency control) family. In snapshot isolation, we can imagine that each transaction is given its own version, or snapshot, of the database when it begins. When the transaction is ready to commit, it’s aborted if a conflict is present.
However, SI is incomparable to RR since it permits Write skew and RR permits at least some phantoms. Wait, what phantom is?
The Phantom phenomenon occurs when we do some predicate-based query (SELECT WHERE predicate) and another transaction modifies the data matched with predicate so the subsequent query returns a different result.
And, finally, no phenomena described are allowed at a serializable level.
Closing thoughts
Of course, this is only a beginning since there much more consistency models to investigate (left branch of our map) that a better described with a distributed systems in mind. I wish I write the second part blog post in some distant future.
References
- http://web.stanford.edu/class/cs145/
- http://www.bailis.org/blog/linearizability-versus-serializability/
- http://www.bailis.org/blog/when-is-acid-acid-rarely/
- https://blog.acolyer.org/2016/02/24/a-critique-of-ansi-sql-isolation-levels/
- https://github.com/aphyr/distsys-class
- https://aphyr.com/posts/313-strong-consistency-models
- http://www.vldb.org/pvldb/vol7/p181-bailis.pdf
- http://publications.csail.mit.edu/lcs/pubs/pdf/MIT-LCS-TR-786.pdf
- Distributed Systems Concepts and Design
- Database System Concepts